


Without computer modeling, it would be extraordinarily difficult to predict protein structures simply through the analysis of genome sequence data. In fact, the analysis of such data might be as helpful as reading tea leaves. DNA sequence data collected from assorted environments has helped researchers generate 3-D models of more than 600 protein families for which the structures were previously unknown.
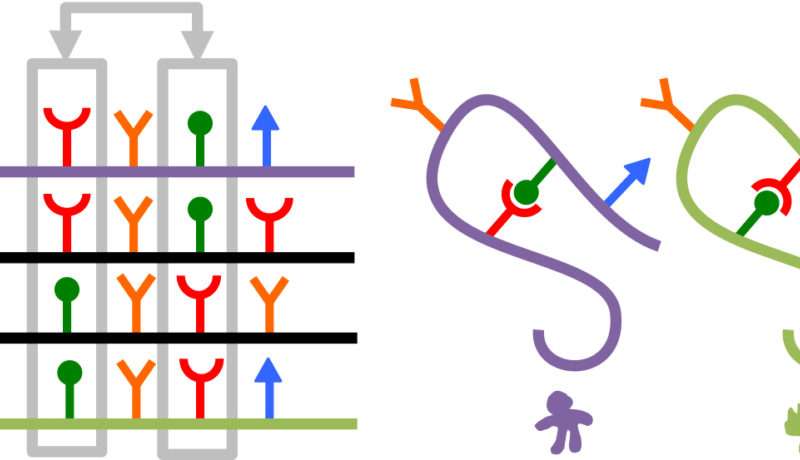
Sufficient data for protein structure prediction, demonstrates a new study, may be obtained through metagenomics, the sequencing of DNA from environmental samples. Metagenomics has often been used to characterize the genomic diversity of microbial communities. The metagenomic data enabled protein sequence comparisons across an array of species, which lent a statistical power to the predictions that would otherwise not have been possible.
Combining with other disciplines and especially driven bydisciplines like structural genomics, protein crystallography extends from analyzing the simple three-dimensional structure of protein to studying the structure of various biological macromolecules and complexes, to focus on the relationship between structure and function. In pharmaceutical R&D, protein crystallographic structure is widely and significantly used in structure-based novel drug design.
There are close to 15,000 protein families in the database Pfam. For nearly a third (4752) of these protein families, there is at least one protein in each family that already has an experimentally determined structure. For another third (4886) of the protein families, comparative models could be built with some degree of confidence. For the final third (5211), however, no structural information exists.
A team led by University of Washington’s David Baker in collaboration with researchers at the U.S. Department of Energy Joint Genome Institute (DOE JGI) has reported that structural models have been generated for hundreds of protein families that previously had no structural information available. Details appeared January 20 in the journal Science, in an article entitled, “Protein Structure Ddetermination Using Metagenome Sequence Data.”
The article describes how Baker’s lab used its protein structure prediction server Rosetta to analyze metagenomic sequences publicly available on the Integrated Microbial Genomes (IMG) system run by the DOE JGI.
“We show that Rosetta structure prediction guided by residue–residue contacts inferred from evolutionary information can accurately model proteins that belong to large families and that metagenome sequence data more than triple[s] the number of protein families with sufficient sequences for accurate modeling,” wrote the authors of the Science article. “We then integrate metagenome data, contact-based structure matching, and Rosetta structure calculations to generate models for 614 protein families with currently unknown structures.”
The authors pointed out that structural models were generated for 206 membrane proteins. Also, 137 structural models were found to contain folds not represented in the Protein Data Bank. “This approach,” the authors added, “provides the representative models for large protein families originally envisioned as the goal of the Protein Structure Initiative at a fraction of the cost.”
“A large number of protein families (in Pfam) have low number of sequences,” said study first author Sergey Ovchinnikov, a graduate student in the Baker lab. “This resulted in two consequences: (1) nobody cared about these families (since they were small); and, (2) co-evolution methods could not be applied to study them. With metagenomics, we found that some of these neglected families with only a handful of sequences so far, can now become as large as some of the most studied ones, when metagenomics data are taken into account! Moreover, we can offer a 3D model of a representative sequence from the family. We hope this will spark interest in some of these families.”
Armed with genome sequences, researchers like Baker have been able to identify sets of amino acids that evolve simultaneously, even though they are nowhere near each other on the unfolded chain. Such events suggest that these amino acids are neighbors in the folded protein, offering researchers hints as to the protein’s structure. Structural proximity can suggest a functional relationship and thus natural selection, acting on the function, can favor not just one amino acid but all that are in the set.
Nikos Kyrpides, DOE JGI Prokaryote Super Program head, emphasized that the collaboration between the Baker lab and the DOE JGI allowed the team to come up with a powerful way of predicting structures and structural alignments.
“Such efforts, were previously restricted on protein families generated from sequences found on the isolate genome only,” he said. “These genomes comprise about 200 million sequences. As expected, when we added on those our metagenomics data, harnessing the 5 billion assembled metagenome sequences available on our IMG/M database, we were able to dramatically increase the coverage of many of the known protein families. Efforts like this one heavily depend on the availability of assembled metagenomics sequences, which is an advantage the DOE JGI brings to the table with our high-quality assemblies.”
 Share:
Share:
 Relevant
news
Relevant
news







 marketing@medicilon.com
marketing@medicilon.com

